

What Is a File Hash? A 6-Minute Definition & Explanation
 (5 votes, average: 5.00 out of 5)
(5 votes, average: 5.00 out of 5)F4baaa8135e0f9a993f0258a4d095db475096896bd3adb48369f1f70c1f0d9d4. Wondering what that is? It’s the file hash for VLC for Windows. Explore the meaning behind gibberish strings like this that are used by many but known by few
In 2021, IBM reports that organizations took an average of nine months to identify and contain a data breach. That’s 277 days — more than enough time even for the minimally skilled cybercriminal to wreak havoc using the data they managed to get ahold of.
With 60% of cybersecurity professionals regarding malware (including ransomware) as one of the top threats, organizations are adding file hashing to their data protection arsenals.
But what is a file hash, exactly? Did you try to understand what it was about before but the explanations you found were too long and complicated? Then look no further. Discover our down-to-earth, six-minute file hash definition. Find out what a file hash is, how it works, and why it can keep users and organizations safe from malware and data breaches.
What Is a File Hash and What Does It Do?
A file hash is a unique signature for data that helps to identify it in a verifiable way. A file hash can be used for various purposes, including protecting the integrity of files, software, and data (i.e., proving that no one has tampered with the data) and deduping (de-duplicating) data.
A hash digest (i.e., the output of a hash function, which is also sometimes called a hash value) is a bit like a file’s fingerprint, and much like a human fingerprint, it’s also used for authenticating someone’s (or something’s) identity. However, a file hash does much more than that. It can also be used to:
- Ensure the integrity of a file,
- Help you protect files or software code from tampering, and
- Protect stored passwords.
Think of a file hash much like how you use labels to identify files in a filing cabinet. How? This is done through applying a mathematical formula (more on that in a few minutes) that transforms any data input of any size into a unique, fixed-length hexadecimal string.
Here’s a quick and basic overview of how hashing works:
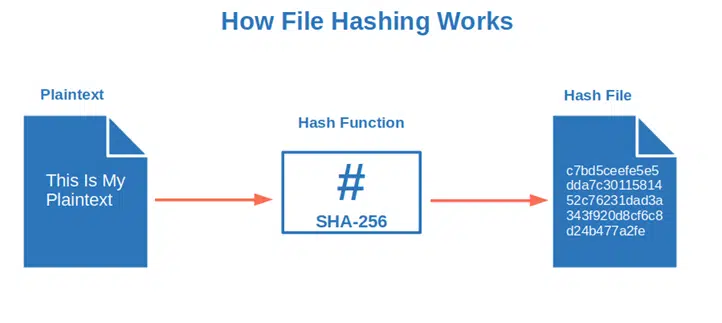
Pretty neat, huh? It’s surely handy in a digital world where in 76% of the 2021 cyber attacks observed by Truesec, cybercriminals obtained full control of the hacked systems in just two hours.
Curious about the different purposes of a file hash? Don’t miss our next article that explores the different roles that a file hash can fill in the digital world.
The 5 File Hash Characteristics
With the file hash definition done and dusted, let’s get to know our file hash better and discover its most important features. Don’t have time to go through the whole chapter? No worries. Check out our summary table to get a flash overview:
| File Hash Properties | Definition (What This Means) |
|---|---|
| 1. Irreversibility | Virtually impossible to reverse engineer. |
| 2. Deterministic | No matter the size of the original data, the hash file (i.e., output) will always be of the same size. |
| 3. Collisions Resistance | Nearly impossible to get two different inputs with the same output (hash). |
| 4. Avalanche Effect | Any change to the input will result in a totally different output. |
| 5. Fast or slightly slower computational speed, depending on needs | One size doesn’t fit all. Choose between fast or slower algorithms as necessary. |
The ideal hash file has the following characteristics:
1. It’s irreversible. In plain English, it’s basically impossible to determine the original data from the hash. Take a SHA-256 file hash as an example (i.e., one of the most used hashing algorithms, more on that in a minute). To reverse engineer it, you’d have to guess an average of 2^256 random hashes. Do you think it’s a small number? Find out in this short and entertaining video that explains what 2^256 really means:
2. It’s deterministic. This means that no matter the size of the original data, the hash file (i.e., output) will always be of the same extent. Want to use the SHA-256 algorithm to hash a sentence? You’ll get a 64 hexadecimal characters file hash. Do you want to hash the whole Encyclopedia Britannica with the same algorithm? You’ll get exactly another 64 hexadecimal characters file hash.
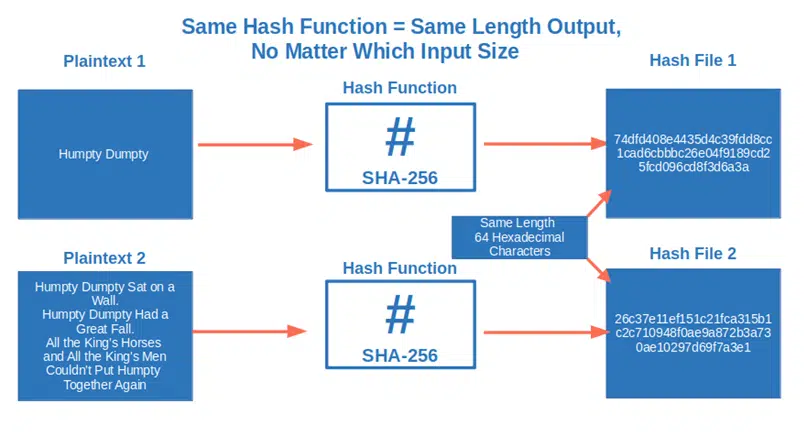
3. It’s collision resistant. Think about the file hash definition at the beginning of this article. It mentions a “unique” output. This indicates that it’s nearly impossible finding two different inputs with the same output (hash value or digest). And the stronger the algorithm you choose to calculate the hash digest, the smaller the possibility of a collision (i.e., finding a duplicate hash output).
4. It has an avalanche effect. Any change to the input will result in a totally different output. One day, by mistake, I put salt in my friend’s coffee instead of sugar. Well, that small change transformed a delicious espresso into a disgusting concoction. Got the idea?

This is another example of how a small change (e.g., one number in the barcode) can make an enormous difference sometimes in terms of identifying products. Likewise, if you were to apply the concept of this example to hashing, the barcode represents the hashing input and the smartphone or teapot represents the hashing output (hash digest). If you change the input by just one number, the resulting output will be entirely different.
5. Its computational speed can be fast or slightly slower, depending on needs. Yup, in this case, one size doesn’t fit all. Hash files have several different purposes. Choose between fast or slower algorithms as necessary. Do you want to use your hash file to help you establish a secure internet connection? You’ll need speed to avoid keeping your website visitors waiting too long to view your page. Do you want to protect your passwords from brute-force attacks, the fourth top infection vector in 2021? Hash your passwords using a slow algorithm. Doing this will slow down your attackers’ fraudulent login attempts, too.
What Kind of Hashing Algorithms Are Available?
In the previous chapters, we’ve used the hashing algorithm SHA-256 as an example. But hashing algorithms are a big clan, and SHA-256 has many siblings and cousins. Let me introduce you to some of the most common families that are part of the hashing algorithm clan, also defined by the National Institute of Standards (NIST):
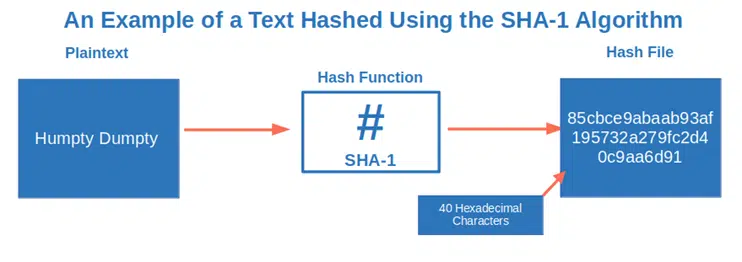
- The secure hash algorithm (SHA) family. This includes SHA-256, which is part of the SHA-2 family. It also includes SHA-1, deprecated since 2017 as vulnerable to brute force attacks, and the SHA-3 group (e.g., SHA-3-512).
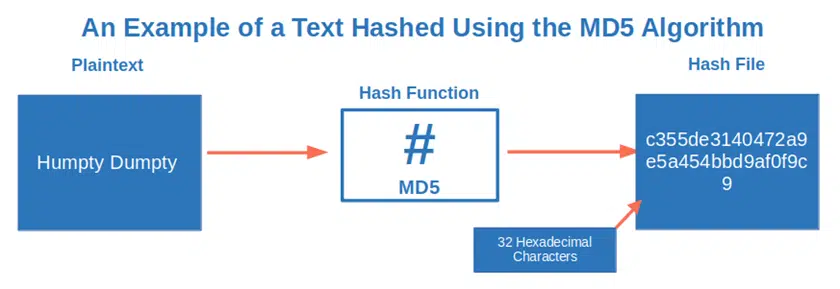
- The message digest (MDA) family. It includes one of the most insecure algorithms, MD5.
- The RACE integrity primitives evaluation message digest (RIPEMD) family. This is composed of four variations with different cryptographic strengths. The second “born” in the family, RIPEMD-160 is used by Bitcoin to create Bitcoin addresses. (However, it’s not the only hash function used for Bitcoin cryptocurrency as it also relies on SHA-256.)
Which one is the best algorithm? It really depends on how you want to use it. The SHA-256 algorithm is surely considered the most secure for certain types of use cases, but the hashing clan is always growing and evolving. Want to meet the latest members? Check out the first four quantum-resistant algorithms presented by NIST in July 2022.
Oh, and if you’re wondering what this quantum mumbo-jumbo is, and how it may affect you, the short video below explains it in under three minutes:
How Is a File Hash Calculated?
OK. You now know what a file hash is and its main properties. We’ve also given you a few examples of the most used hashing algorithms. Now, it’s time to find out how a file hash results from applying a hash function to your original input data. Let’s say you want to get a file hash of the first verse of George Michael’s song “Last Christmas” using the SHA-256 algorithm:
“Last Christmas, I gave you my heart
But the very next day, you gave it away
This year, to save me from tears
I’ll give it to someone special”
- The hashing algorithm divides the input (the above verse) into blocks of equal size.
- Each block is then processed one by one while every single output is added to the next block.
- The file hash (output) is what comes out at the end of the cycle.
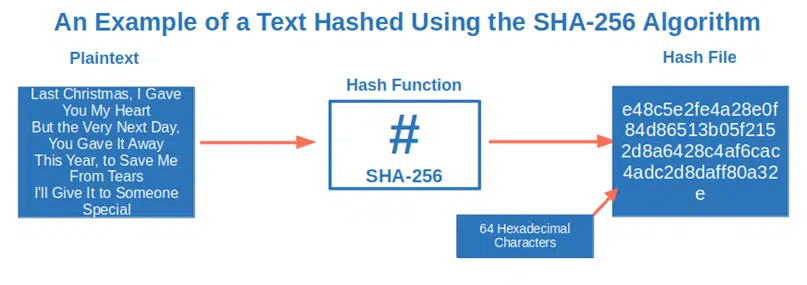
It works a bit like when you bake the Italian “four cups cake” (i.e., torta quattro tazze). You put a cup of self-rising flour (first block) into a kneading machine (your hashing algorithm) and turn it on. You then add the other ingredients/blocks (a cup of corn flour, a cup of sugar, one of milk, and a cup of chocolate chips), one by one, while the machine is mixing everything together. Having the mixture ready to pour into your cake tin is the final output.
Right, the process is pretty clear, but how is the hash file calculated? No fear — you won’t have to do it by hand. You won’t even need a mega-powerful computer to do it. There are several tools available that make file hashing easy as one-two-three. Which ones?
- Windows CertUtil command line program, for example, can help you hash a file in just 60 seconds.
- HashMyFiles, a free standalone tool, can do the calculation for you and supports different hashing algorithms.
Want more choices? Check out the National Cybersecurity and Communication Integration Center (NCCIC) file hashing fact sheet. They have a pretty comprehensive list.
File Hashing Isn’t Encryption
Before we wrap up, just a warning: Don’t confuse file hashing with encryption. No way, José! While they may look similar, and both are cryptographic functions, there are some key fundamental differences:
- Encryption transforms a message or a piece of data into a gibberish string using a cryptographic key. The message can be decrypted using the same key (symmetric encryption) or a private key (asymmetric encryption). This means that, as long as you have the right key, you can always determine the original message. This makes it a two-way function.
- Hashing, on the other hand, is a one-way function that’s used for authentication and file identification. Once the input is hashed, it’s basically impossible to reverse engineer. Hashing is used as a way to verify the integrity of data while simultaneously concealing the original input.
Got it? So, now, “C’mon baby, hash my files!” OK, Jim Morrison wasn’t really saying that when singing the Doors’ song “Light My Fire.” It sounds cool, though. To learn more about what hashing is used for, be sure to check back in the next week or so for another article on the topic.
Final Thoughts on What Is a File Hash? A 6-Minute Definition
That wasn’t too difficult, was it? In a nutshell, a file hash is a unique numerical value calculated using a mathematical function that identifies the content of a file. It takes an input of any size and converts it to a fixed-length data string. And if the file is modified, the hash file will change entirely, too, but its length will remain the same.
Among its characteristics, we’ve found out that a file hash is:
- Collision resistant (i.e., two unique inputs will never have the same output).
- Pre-image resistant (i.e., impractical to determine the original input from the hash digest because it would require too much time and too many resources).
- Deterministic (i.e., an input will always return the same output hash digest).
But what about its purposes? Why is it such a fundamental tool in cybersecurity? Stay tuned because this is the question we’ll answer in more detail in our next article!
